構(gòu)建支撐50萬(wàn)QPS的站內(nèi)未讀消息系統(tǒng)——享讀系統(tǒng)設(shè)計(jì)詳解
引言
在互聯(lián)網(wǎng)應(yīng)用中,站內(nèi)未讀消息系統(tǒng)是維系用戶活躍度與粘性的核心功能之一。當(dāng)面對(duì)如“享讀系統(tǒng)”這樣需要支撐50萬(wàn)Qps(每秒查詢量)的高并發(fā)場(chǎng)景時(shí),傳統(tǒng)的數(shù)據(jù)庫(kù)直接讀寫方案會(huì)迅速成為性能瓶頸。本文將系統(tǒng)性地探討如何設(shè)計(jì)一個(gè)高可用、低延遲、可擴(kuò)展的站內(nèi)未讀消息系統(tǒng),以應(yīng)對(duì)海量實(shí)時(shí)請(qǐng)求的挑戰(zhàn)。
一、 核心挑戰(zhàn)與設(shè)計(jì)目標(biāo)
在50萬(wàn)Qps的壓力下,系統(tǒng)設(shè)計(jì)面臨多重挑戰(zhàn):
- 極致性能與低延遲:用戶對(duì)未讀數(shù)的感知要求幾乎是實(shí)時(shí)的,讀取延遲必須控制在毫秒級(jí)。
- 高并發(fā)寫入:用戶每閱讀一條消息、系統(tǒng)每推送一條新消息,都可能觸發(fā)未讀數(shù)的更新,寫入并發(fā)量巨大。
- 數(shù)據(jù)一致性:在分布式環(huán)境下,保證用戶看到的未讀計(jì)數(shù)準(zhǔn)確無(wú)誤,避免出現(xiàn)多讀或少讀。
- 可擴(kuò)展性與高可用:系統(tǒng)需能隨著用戶量增長(zhǎng)平滑擴(kuò)容,且任何單點(diǎn)故障不應(yīng)影響核心服務(wù)。
因此,我們的設(shè)計(jì)目標(biāo)聚焦于:讀擴(kuò)散、異步化、內(nèi)存優(yōu)先、最終一致性。
二、 架構(gòu)設(shè)計(jì)總覽
整體架構(gòu)采用分層、分模塊的設(shè)計(jì)思想,核心分為三層:
- 接入層:采用高性能網(wǎng)關(guān)(如Nginx、API Gateway)進(jìn)行負(fù)載均衡與請(qǐng)求路由,并實(shí)現(xiàn)限流、熔斷等保護(hù)措施。
- 邏輯服務(wù)層:
- 消息投遞服務(wù):負(fù)責(zé)處理新消息的創(chuàng)建與分發(fā)邏輯,將“有新消息”這個(gè)事件異步通知給計(jì)數(shù)服務(wù)。
- 未讀計(jì)數(shù)服務(wù):系統(tǒng)的核心,負(fù)責(zé)未讀計(jì)數(shù)的增、刪、改、查。它不直接處理業(yè)務(wù)邏輯,而是作為計(jì)數(shù)緩存的管理者。
- 會(huì)話/列表服務(wù):負(fù)責(zé)管理用戶的消息會(huì)話列表和消息內(nèi)容本身,與計(jì)數(shù)服務(wù)解耦。
- 數(shù)據(jù)存儲(chǔ)層:采用多級(jí)混合存儲(chǔ)策略。
三、 核心設(shè)計(jì)策略
1. 讀寫分離與讀擴(kuò)散
放棄為每條消息單獨(dú)標(biāo)記已讀/未讀的“寫擴(kuò)散”模式(存儲(chǔ)開銷和寫入壓力巨大)。采用 “讀擴(kuò)散” 模式:
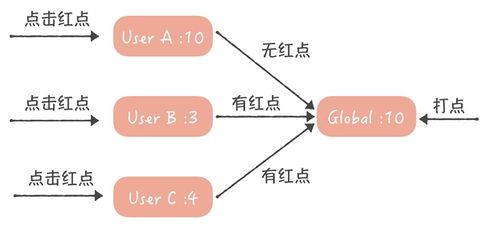
- 未讀集存儲(chǔ):系統(tǒng)只為每個(gè)用戶維護(hù)一個(gè)未讀消息ID的集合(或一個(gè)總計(jì)數(shù))。
- 判定邏輯:當(dāng)用戶查詢某個(gè)會(huì)話的未讀數(shù)時(shí),由服務(wù)端實(shí)時(shí)計(jì)算:該會(huì)話的最新消息ID與用戶已讀的最后一條消息ID之間的差值(或檢查消息ID是否在用戶的未讀集合中)。這將對(duì)數(shù)據(jù)庫(kù)的頻繁寫入轉(zhuǎn)移為對(duì)緩存的高效讀取。
2. 緩存優(yōu)先與存儲(chǔ)選型
- 一級(jí)緩存(熱點(diǎn)數(shù)據(jù)):使用 Redis 集群作為核心計(jì)數(shù)存儲(chǔ)。
- 存儲(chǔ)結(jié)構(gòu):為每個(gè)用戶維護(hù)一個(gè)
Hash,鍵為uid,字段為會(huì)話ID(sid),值為該會(huì)話的未讀數(shù)。可以設(shè)置一個(gè)總未讀數(shù)的字段。
- 優(yōu)勢(shì):內(nèi)存讀寫,性能極高;豐富的數(shù)據(jù)結(jié)構(gòu)(Hash, Sorted Set)能很好支撐聚合查詢和范圍查詢。
- 容量規(guī)劃:以2億用戶,每個(gè)用戶平均10個(gè)活躍會(huì)話估算,存儲(chǔ)量可控,可通過(guò)集群分片(如Codis, Redis Cluster)輕松擴(kuò)展。
- 二級(jí)備份與持久化:使用 Apache Cassandra 或 TiDB 等分布式數(shù)據(jù)庫(kù)。
- 作用:持久化存儲(chǔ)全量的用戶-會(huì)話未讀關(guān)系,作為Redis數(shù)據(jù)的備份和恢復(fù)源。
- 選型理由:它們具有高寫入吞吐、線性擴(kuò)展能力,適合海量數(shù)據(jù)的最終一致性存儲(chǔ)。
- 消息同步:采用 異步雙寫 或 Write-Through 策略。所有計(jì)數(shù)更新先寫入Redis,確保前端響應(yīng)速度;隨后通過(guò)消息隊(duì)列(如Apache Kafka, RocketMQ)異步同步到分布式數(shù)據(jù)庫(kù),實(shí)現(xiàn)最終一致性。
3. 計(jì)數(shù)更新策略——增量與合并
直接為每條新消息實(shí)時(shí)更新全局計(jì)數(shù)會(huì)給Redis帶來(lái)巨大壓力。優(yōu)化方案:
- 本地累加:在消息投遞服務(wù)中,為每個(gè)用戶維護(hù)一個(gè)小的內(nèi)存累加器(如Guava Cache),在短時(shí)間內(nèi)(如1秒)將多次增量合并為一次更新操作,再批量寫入Redis。這能極大減少對(duì)Redis的網(wǎng)絡(luò)請(qǐng)求和寫入命令。
- 延遲更新:對(duì)于非強(qiáng)實(shí)時(shí)性的全局總未讀數(shù),可以接受秒級(jí)的延遲更新,通過(guò)后臺(tái)任務(wù)定期從各會(huì)話計(jì)數(shù)聚合計(jì)算。
4. 容災(zāi)與數(shù)據(jù)一致性保障
- Redis數(shù)據(jù)持久化與備份:開啟AOF和RDB,結(jié)合哨兵或集群模式實(shí)現(xiàn)高可用。
- 兜底查詢:當(dāng)Redis集群發(fā)生故障或緩存未命中時(shí),服務(wù)應(yīng)能自動(dòng)降級(jí),從分布式數(shù)據(jù)庫(kù)中查詢并回種緩存。為防止緩存擊穿,需使用分布式鎖或布隆過(guò)濾器。
- 最終一致性核對(duì):設(shè)立定時(shí)對(duì)賬任務(wù),比對(duì)Redis與分布式數(shù)據(jù)庫(kù)中的計(jì)數(shù)差異,并進(jìn)行修復(fù),確保數(shù)據(jù)長(zhǎng)期準(zhǔn)確。
四、 關(guān)鍵流程示例
- 用戶查詢未讀數(shù)(讀流程):
- 請(qǐng)求到達(dá)網(wǎng)關(guān),路由至未讀計(jì)數(shù)服務(wù)。
- 服務(wù)直接查詢Redis集群中對(duì)應(yīng)用戶的Hash結(jié)構(gòu),獲取各會(huì)話未讀數(shù)及總數(shù)。
- 毫秒級(jí)返回結(jié)果。
- 新消息到達(dá)(寫流程):
- 消息投遞服務(wù)將新消息持久化到消息庫(kù)。
- 向Kafka發(fā)送一個(gè)事件:
{"uid": 123, "sid": 456, "increment": 1}。
- 未讀計(jì)數(shù)服務(wù)消費(fèi)該事件,先在本地累加器合并增量。
- 累加器定時(shí)(如每秒)將合并后的增量(例如,
{123: {456: 5}}表示用戶123在會(huì)話456的未讀數(shù)需增加5),通過(guò)HINCRBY命令批量更新至Redis。
- 另一個(gè)消費(fèi)者將同樣的更新異步寫入Cassandra進(jìn)行持久化。
五、 性能估算與優(yōu)化
- Redis集群估算:假設(shè)50萬(wàn)Qps全部為讀請(qǐng)求,單Redis實(shí)例(分片)處理約8-10萬(wàn)Qps,則需要約5-7個(gè)分片組成的集群。實(shí)際中讀寫混合,需根據(jù)比例增加資源。通過(guò)Pipeline和批量命令可進(jìn)一步提升吞吐。
- 網(wǎng)絡(luò)與序列化:使用高性能序列化協(xié)議(如Protobuf),優(yōu)化網(wǎng)關(guān)與服務(wù)間的網(wǎng)絡(luò)通信。
- 監(jiān)控與調(diào)優(yōu):建立完善的監(jiān)控體系(如Prometheus + Grafana),實(shí)時(shí)跟蹤Qps、延遲、緩存命中率、數(shù)據(jù)庫(kù)負(fù)載等核心指標(biāo),以便動(dòng)態(tài)調(diào)整和擴(kuò)容。
結(jié)論
設(shè)計(jì)一個(gè)支持50萬(wàn)Qps的站內(nèi)未讀消息系統(tǒng),關(guān)鍵在于將核心的計(jì)數(shù)功能從傳統(tǒng)數(shù)據(jù)庫(kù)中剝離,構(gòu)建一個(gè)以內(nèi)存緩存(Redis)為核心、異步持久化為保障的獨(dú)立服務(wù)體系。通過(guò)采用“讀擴(kuò)散”、增量合并、多級(jí)緩存、最終一致性等設(shè)計(jì)模式,能夠有效化解高并發(fā)壓力,實(shí)現(xiàn)低延遲、高可用的目標(biāo)。享讀系統(tǒng)的實(shí)踐表明,清晰的分層架構(gòu)和針對(duì)性的技術(shù)選型,是應(yīng)對(duì)此類規(guī)模挑戰(zhàn)的堅(jiān)實(shí)基礎(chǔ)。系統(tǒng)上線后,仍需持續(xù)監(jiān)控和迭代,以應(yīng)對(duì)未來(lái)可能增長(zhǎng)的業(yè)務(wù)量。
如若轉(zhuǎn)載,請(qǐng)注明出處:http://www.kjkjtdwh.cn/product/17.html
更新時(shí)間:2026-05-20 09:54:19